 Flock
Flock  Flock
Flock OpenAI a annoncé hier la sortie de son nouveau grand modèle de langage : o1. Celui-ci apporte de nouvelles étapes d'évaluation de sa réponse avant de la proposer à l'utilisateur. Néanmoins, dans sa version proposée publiquement, il ne peut s'appuyer que sur ses données d'entrainement et n'est utilisable que sur du texte. Le prix pourrait aussi être un frein à son utilisation.
L'entreprise qui a popularisé les grands modèles de langage avec son ChatGPT a présenté jeudi 12 septembre, dans un billet de blog, son nouveau modèle nommé o1. Celui-ci était très attendu sous le nom de code interne qui circulait jusque-là : Strawberry.
En fait, o1 est plutôt une nouvelle famille de modèles de l'entreprise. Deux d'entre eux sont disponibles sur ChatGPT et via l'API d'OpenAI : o1-preview et o1-mini. Cette famille est particulière, car elle introduit un nouveau mécanisme dans les grands modèles de langage. OpenAI dit qu'ils peuvent « produire une longue chaîne de pensée interne avant de répondre à l'utilisateur ».
Les grands modèles de langage sont, comme l'expliquaient les chercheuses Emily Bender, Timnit Gebru, Angelina McMillan-Major et Margaret Mitchell, des robots perroquets probabilistes qui génèrent du texte en fonction de probabilités de retrouver des groupes de mots dans les données d'entrainement, mais sans se fonder « sur une intention de communication, un modèle du monde ou un modèle de l'état d'esprit du lecteur ».
Tout le monde a pu constater que cette conception à l'origine de l'IA générative engendre parfois des textes qui « hallucinent » des faits, ou plutôt qui ne reflètent pas la réalité. Les entreprises d'IA générative essayent donc d'améliorer leurs modèles pour éviter ce genre de problèmes.
Un nouveau système utilisant l'apprentissage par renforcement
OpenAI explique qu'o1 est entrainé avec la technique de « l'apprentissage par renforcement pour effectuer des raisonnements complexes » qui « apprend au modèle à penser de manière productive en utilisant sa chaîne de pensée dans le cadre d'un processus de formation très efficace sur le plan des données ».
Et ce système semble bien améliorer les résultats du modèle : « plus il réfléchit longtemps, plus il obtient de bons résultats dans les tâches de raisonnement. Cela ouvre une nouvelle dimension pour la mise à l'échelle. Nous ne sommes plus bloqués par le pré-entraînement », explique Noam Brown, un chercheur qui travaille pour OpenAI.
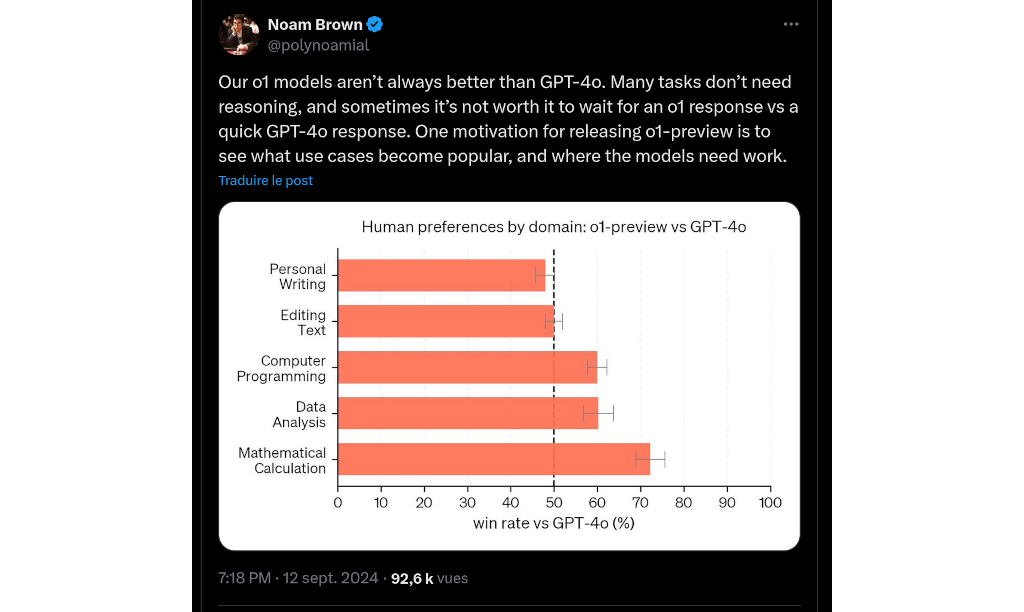
Il tempère quand même son propos en concédant : « nos modèles o1 ne sont pas toujours meilleurs que GPT-4o. De nombreuses tâches ne nécessitent pas de raisonnement, et parfois, il n'est pas intéressant d'attendre une réponse o1 alors qu'une réponse rapide de GPT-4o suffit ».
« Le pré-entraînement pourrait décroitre »
Le chercheur de NVIDIA Jim Fan s'est enthousiasmé de l'annonce : « nous voyons enfin le paradigme de la mise à l'échelle du temps d'inférence popularisé et déployé en production ». Pour lui, la sortie de o1 montre qu'il n'y a pas « besoin d'un modèle énorme pour effectuer un raisonnement ».
Il explique que dans les modèles de langage, « de nombreux paramètres sont dédiés à la mémorisation des faits, afin d'obtenir de bons résultats dans des tests de référence comme des questions/réponses triviales ».
Mais o1 montre que, selon OpenAI, il serait possible de remonter la piste du « raisonnement » à partir de la base de connaissance. La société parle d’un « petit "noyau de raisonnement" qui est capable d'appeler des outils comme le navigateur et le vérificateur de code ». Selon lui, « le pré-entraînement pourrait décroitre », grâce à ce système.
Dans son message, Jim Fan semble impressionné par le travail de ses concurrents (et anciens collègues puisqu'il y a été stagiaire) : « OpenAI a dû comprendre la loi d'échelle de l'inférence il y a longtemps, ce que le monde universitaire vient tout juste de découvrir ». Il cite deux articles scientifiques (celui-ci et celui-là) mis en ligne au milieu de l'été sur la plateforme de preprint arXiv.
Une utilisation en production très limitée
Pour l'instant, l'utilisation d'o1 pour le grand public semble cependant limité puisqu'OpenAI ne permet pas de traiter des images ou des documents avec. L'entreprise limite aussi très fortement sa fréquence d'utilisation : « au lancement, les limites hebdomadaires seront de 30 messages pour o1-preview et de 50 pour o1-mini », précise-t-elle. Elle ajoute qu'elle s'efforce « d'augmenter ces fréquences et de permettre à ChatGPT de choisir automatiquement le bon modèle pour un message donné ».
Enfin, les prix affichés par l'entreprise ne sont pas donnés : o1-preview est proposé à 15 dollars pour 1 million de jetons d'entrée et 60 dollars pour 1 million de jetons de sortie. C'est respectivement trois et quatre fois plus chers que les prix qu'OpenAI propose pour GPT-4o.
o1-mini est moins cher : 3 dollars le million de jetons d'entrée et 12 pour le million de jeton de sortie. L'entreprise promet aussi qu'elle « prévoit également d'offrir l'accès à o1-mini à tous les utilisateurs de ChatGPT Free ».







Commentaires (15)
#1
#1.1
#1.2
Je n’ai aucune idée du coût réel mais je pense que c’est globalement très très cher si c’est utilisé industriellement.
#1.3
On trouve facilement des simulateurs en ligne, le premier que je trouve https://www.prompttokencounter.com/ , en général avec 1 token tu fais pas grand chose (voir rien du tout).
#1.5
"Salade de fruit" = 4 tokens !
#1.8
Je viens de faire un test par curiosité.
Dans une formulation de question :
"C" => 1 token
"C'est", "est-ce" => 3 token
"S'agit-il" => 3 à 4 token
Un exemple de plus que LLM vont créer de l'emploi, il faudra former les utilisateurs à une conduite économe
#1.9
Il faut aussi exiger au LLM d'être concis, car GPT a tendance à s'étaler inutilement et donc générer du token, et donc de la facturation "sortante".
#1.4
#1.6
#1.7
#2
#2.1
#2.2
Remarque, c'est le même niveau qu'une certif Cloud à la mords moi le nœud.
#2.3
Amen.
#3
Dans le fonctionnement, j'ai l'impression que l'idée se rapproche d'AutoGPT, un concept fort intéressant.